1
(1)
k1 and k2 are kernel functions, Mercer Theorm: K1 and K2 are positive semidefinte:
∀x∈X={x1,…,xN},xTKix>0,i=1,2
therefore:
$\forall x \in \mathbb{X}: $
xTK3x=xT(a1K1+a2K2)x=a1xTK1x+a2xTK2x≥0
Using Mercer theorm, k3 is a kernel function.
(2)
assume f(X)=[f(x1),…,f(xN)]
xTK4x=xTf(X)Tf(X)x=(f(X)x)Tf(X)x≥0
therefore k4 is a positive definite kernel function.
2
| 模型序号 |
模型 |
偏差 |
方差 |
| (1) |
在线性回归模型中增加权重的正则化项 |
增大 |
减小 |
| (2) |
对决策树进行剪枝处理 |
增大 |
减小 |
| (3) |
增加神经网络中隐含层节点的个数 |
减少 |
增加 |
| (4) |
去除支持向量机中所有的非支持向量 |
不变 |
不变 |
3
(1)
w,b,ξimin21∥w∥2+Ci=1∑m~ξi+Cki=m~+1∑mξisubject toyi(wTxi+b)≥1−ξiξi≥0,i=1,…,m
其中 i=1,…,m~ 为正例,i=m~+1,…,m 为反例。
(2)
Lagranian:
L(w,b,α,ξ,μ)=21∥w∥2+Ci=1∑m~ξi+Cki=m~+1∑mξi+i=1∑mαi(1−ξi−yi(wTxi+b))−i=1∑mμiξi
∂w∂L=0,∂b∂L=0,∂ξi∂L=0
w0CkC=i=1∑mαiyixi=i=1∑mαiyi=αi+μi=αi+μii=1,…,m~i=m~+1,…,m
dual problem:
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjsubject toi=1∑mαiyi=00≤αi≤C,i=1,…,m~0≤αi≤kC,i=m~+1,…,m
KKT:
αi≥0,μi≥0yif(xi)−1+ξi≥0αi(yif(xi)−1+ξi)=0ξi≥0,μiξi=0
4
(1)
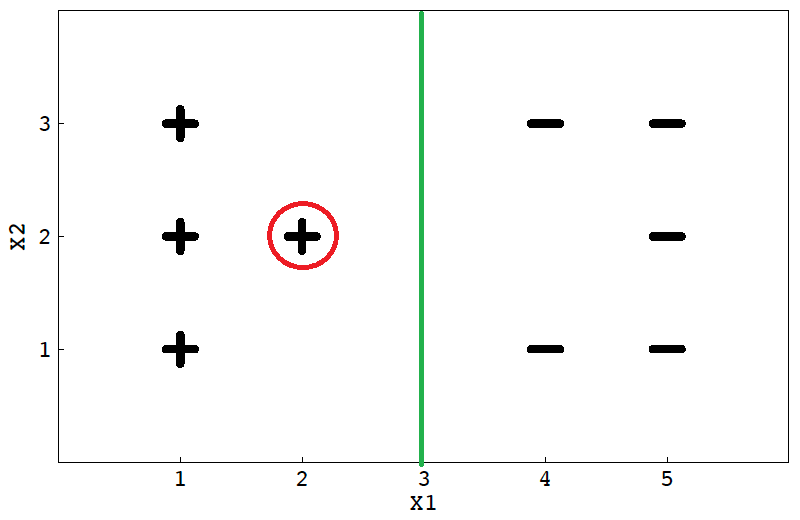
将在 x1=3直线上,C很大的时候对错误的容忍度降低,将会强制划分。
(2)
去掉 x1=2 或者x1=4 上的任一点都会得到新的决策边界,因为它距离边界很近,对边界影响很大。
(3)
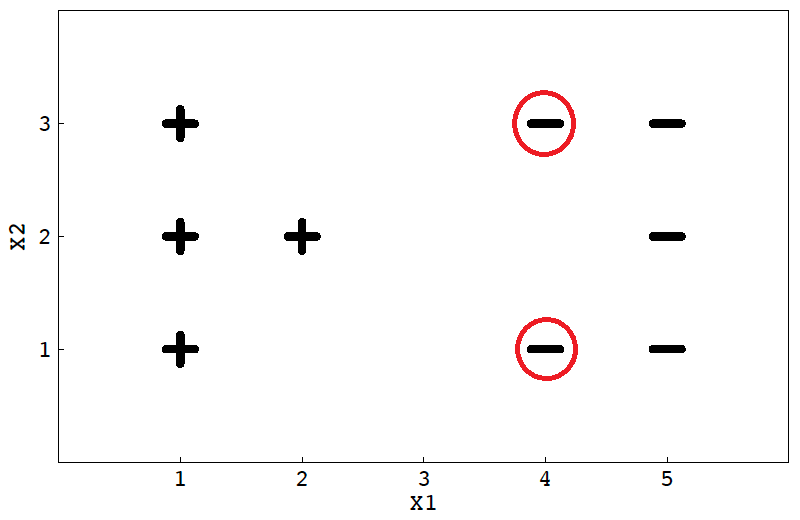
同样的,在边界附近的点对边界影响很大。
(4)
- 使用3中不同的惩罚系数。
- 对样本预处理,欠采样;如对多一部分做剔除;过采样;对少的一部分做插值等。
- 忽略部分非支持向量,保证支持向量数量尽可能的一致。
(5)
∥ϕ(x)−ϕ(z)∥=<ϕ(x)−ϕ(z),ϕ(x)−ϕ(z)>=<ϕ(x),ϕ(x)>+<ϕ(z),ϕ(z)>−2<ϕ(x),ϕ(z)>=K(x,x)+K(z,z)−2K(x,z)
5
f(x∣θ)={πθ210∥x∥≤θotherwiseL(θ)=i=1∏nf(X∣θ)=i=1∏nπθ21s.t.max∥Xi∥≤θ
log:
ℓ(θ)=lnL=−2nln(π1)lnθs.t.max∥Xi∥≤θ
maxℓ we get:
θ^=max(∥Xi∥)
6
(1)
Using naive Bayes classifier
P(y=1)=53P(y=0)=52P(x1=1∣y=1)=32P(x1=1∣y=0)=21P(x2=1∣y=1)=31P(x2=1∣y=0)=21P(x3=0∣y=1)=0P(x3=0∣y=0)=21P(x4=1∣y=1)=32P(x4=1∣y=0)=21
P{y=1∣x=(1,1,0,1)}=p(x)1p(y=1)P(x1=1∣y=1)P(x2=1∣y=1)P(x3=0∣y=1)P(x4=1∣y=1)=p(x)1⋅53⋅32⋅31⋅0⋅32=0P{y=0∣x=(1,1,0,1)}=p(x)1P(y=0)P(x1=1∣y=0)P(x2=1∣y=0)P(x3=0∣y=0)P(x4=1∣y=0)=p(x)1⋅52⋅21⋅21⋅21⋅21=p(x)152
(2)
经过Laplacian Correction:
P(y=1)=74P(y=0)=73P(x1=1∣y=1)=53P(x1=1∣y=0)=42P(x2=1∣y=1)=52P(x2=1∣y=0)=42P(x3=0∣y=1)=51P(x3=0∣y=0)=42P(x4=1∣y=1)=53P(x4=1∣y=0)=42
P{y=1∣x=(1,1,0,1)}=p(x)1p(y=1)P(x1=1∣y=1)P(x2=1∣y=1)P(x3=0∣y=1)P(x4=1∣y=1)=p(x)1⋅74⋅53⋅52⋅51⋅53=p(x)0.016P{y=0∣x=(1,1,0,1)}=p(x)1P(y=0)P(x1=1∣y=0)P(x2=1∣y=0)P(x3=0∣y=0)P(x4=1∣y=0)=p(x)1⋅73⋅42⋅42⋅42⋅42=p(x)0.026
7
(1)
Bayes网络 B=<G,Θ> 将属性 x1,…,xd 的联合概率分布定义为:
PB(x1,…,xd)=i=1∏dPB(xi∣πi)=i=1∏dθxi∣πi
其中 πi 为属性 xi 在结构 G 中的父节点集, θxi∣πi=PB(xi∣πi) 为每个属性的条件概率表。
联合概率分布:
P(x1,…,x7)=P(x1)P(x2)P(x3)P(x4∣x1,x2,x3)P(x5∣x1,x3)P(x6∣x4)P(x7∣x4,x5)
(2)
若观测到 x4 或 x6 或 x7的状态,则x1,x2不相互独立。若对于 x4,x6,x7状态未知,则x1,x2相互独立。
(3)
是独立的。使用 D-Seperation 方法,构造道德图,发现去除 x4 后, x6 与 x7 分属独立分支。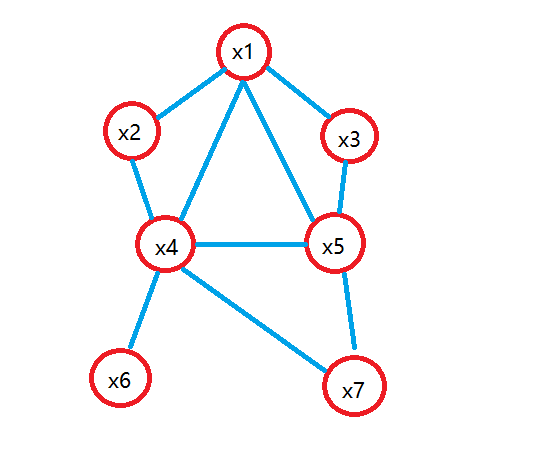
8
(1)
里程:
| 里程\引擎 |
好 |
差 |
| 高 |
0.5 |
0.5 |
| 低 |
0.75 |
0.25 |
空调:
车的价值:
| 引擎 |
空调 |
高 |
低 |
| 好 |
可用 |
0.75 |
0.25 |
| 差 |
可用 |
0.22 |
0.77 |
| 好 |
不可用 |
0.6 |
0.4 |
| 差 |
不可用 |
0 |
1 |
(2)
若车的价值未知,则引擎与空调独立,有:
P(引擎=差,空调 = 不可用)=P(引擎=差)P(空调 = 不可用)=[P(引擎=差∣里程=高)P(里程=高)+P(引擎=差∣里程=低)P(里程=低)]P(空调 = 不可用)=[0.5×0.5+0.25×0.5]0.375=0.14